My paper on exit polls was rejected by the first peer review. Primarily due to the bias against using exit polls for election accuracy by academic researchers. Because they don’t trust exit polls as a measure of vote count accuracy, they don’t accept my conclusion. This is not surprising – I had journal editors who would reject my paper based on that alone without even considering sending it to reviewers. The journal I finally sent it to was the first one that was willing to at least consider it.
Because this is a controversial conclusion, I needed to include a lot of back up information justifying the conclusion. My original paper was over 8000 words, more than twice their limit. It was sent back immediately and without any reviews based on that and another minor bookkeeping error I had made. I corrected the bookkeeping error and drastically revised the paper, cutting it down to a bit over 5000 words. I am grateful they were willing to assign reviewers to it, but most of the valid criticisms were due my having cut so much of the supporting documentation out of the revision they got. This is conundrum I have not resolved yet. If I include all of the analyses they wanted to see, I will have a paper longer than peer-reviewed journal publishers are generally willing to accept.
Here is what the reviewers said and my responses to them. The reviewers comments are in italics:
Reviewer: 1
Comments to the Author
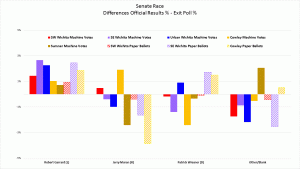
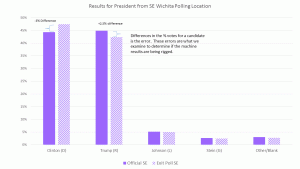
“In the absence of any deliberate manipulation of results, the difference in vote share between the official count and an exit poll (e) will be randomly distributed around zero and relatively small” (p. 6).
That’s a crazy assumption. Significant discrepancy between an official tabulation and a poll estimating the same quantity from a sample of the relevant population can follow from: (a) deliberate manipulation of the tabulation; (b) inadvertent error in the tabulation; (c) inadvertent misrepresentation of behavior by poll respondents; (d) deliberate misrepresentation of behavior by poll respondents; (e) systematic differences between those willing and those unwilling to respond to the survey, in the (almost universal) case where the survey does not cover the whole population; (f) error by the analysts comparing the poll and official results. These authors implicitly assume that (b) through (f) are negligible, which is, frankly, ludicrous.
My response:
My first draft paper presented detailed responses to these alternate explanations – the “Liars, Idiots and Introverts” section covered most of them, with some additional paragraphs scattered in other sections. I toned the section down and then ended up cutting it completely in the version he/she saw. I’ll put it back in, at least the toned down version, before I send it off again.
A priori, (a) is an unlikely culprit most of the time if only because falsifying election results is usually a felony and those rigging the outcomes would be taking large risks. That point is certainly not an “impossibility theorem,” and there are surely some cases of deliberate fraud. But (a) is not a natural first suspect, and pollsters have long warned consumers of polling data not to exaggerate the accuracy of exit (or, indeed, other) polls. See, eg, https://fivethirtyeight.com/features/ten-reasons-why-you-should-ignore-exit/.
My response:
This seems to be a serious bias against using exit poll results as a method of verifying election accuracy. There are certainly limitations to such data particularly when put to use in predicting outcomes or general trends. That was not the aim of this one. I designed this particular exit poll is not a standard design of opinion polls, but a standard design for auditing process results and isolating a problem area to assess the size of the problem. The accuracy of my calculations are based on well understood statistical methods and appropriate for the data.
I find it interesting that there is strong antipathy to using exit poll results for verifying accuracy of election results by political science academics. I have seen no solid reason for the disdain, but it has been common in my queries to editors about whether they would consider the paper at all.
One consequence of adopting this stance regarding exit poll results is that it closes off the only legitimate avenue for voters to assess the accuracy of their precinct results. Voters cannot provide sufficient evidence for academics to take their concerns seriously and start doing something to put out the fire in the theater. Any vocalized suspicion of voting machines being rigged is dismissed as tinfoil hat territory as this reviewer just did above.
I am also troubled by the idea that falsifying election results can be dismissed because it’s illegal and heavily penalized if caught. That’s like declaring a death as being more likely due to natural causes just because murder is rare, illegal and heavily penalized when caught. It does illustrate the difficulty in getting this type of controversial hypothesis through the peer-review system.
I am instructed to limit my comments to 500 words so I’ll raise only a few more specific worries.
Responding to an uncited quotation by Thomas König (probably in an APSR rejection letter) the authors claim that an un-refereed e-book proves that discrepancy between exit polls and official results are fraud. Bollocks.
My response:
This is because I included Jonathon Simon’s “Code Red” book as a reference. There are certainly reasons to be suspicious of a self-published book of this nature. On the other hand, I have the appropriate qualifications to perform a peer review on this book. I’ve read and found the data convincing. This reviewer has scoffed at the publishing venue while demonstrating how difficult it is for such a hypothesis to make it through the peer review process.
What I was trying to express with that citation was the justification for considering the hypothesis at all and why I set up exit polls to evaluate it independently. That the hypothesis that our voting machines are being manipulated is not crazy or ludicrous, but a legitimate concern to voters. I don’t understand why academics in the field of political science are unwilling to give the hypothesis serious consideration, but they don’t appear to be willing to entertain the notion that our voting machines are being rigged with anything but ridicule.
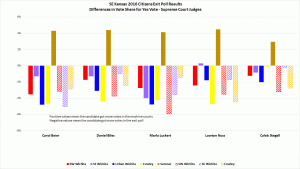
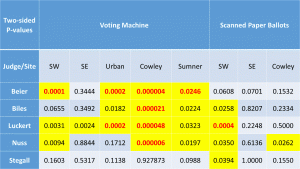
– A second cursory argument against the polls being wrong comes up following the main analysis, when the authors claim that the discrepancies are not correlated with registration skew, but provide not clear details (this is few lines on “Corollary 1” at the top of page 10).
My response:
This section originally had a table and chart and more detail, but I removed it trying to cut it down to an acceptable length. I’ll consider putting this back in, but maybe in an appendix to keep the paper length down.
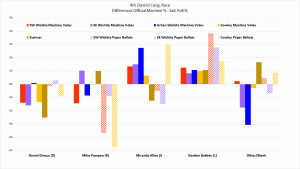
– Finally comes an ANOVA which, for the first time, acknowledges that the poll covered more races than the five justice-recall events. Insofar as systematic differences between responders and non-responders drive poll-tabulation discrepancies, differences across contests might be informative, so it is wise to use all of the information available and not analyze contests in isolation. How informative are the multiple contests depends in part on how strongly correlated are the voting patterns across contest. Generally, a serious analysis of survey-result discrepancies should make use of all of the information at hand. If the authors believe that only the KS SC contests were rigged (unnecessarily as it turns out!?), they can say so explicitly and make better use of the other races. The analysis done through page 9 in this manuscript ignores the other contests and is, accordingly, of limited value.
My response:
In the final submitted version, I took out the analyses of those races. They provide more support for the rigged hypothesis, with four additional anomalies, only one of which has a reasonable alternative explanation. Thinking like a mathematician, since the Judge Races were sufficient to prove deliberate manipulation, the other races did not need to be explicitly covered. For a mathematician this is logical. But based on this comment, that decision was not a good choice.
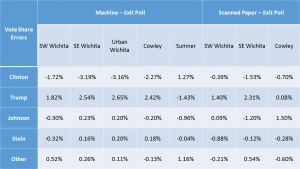
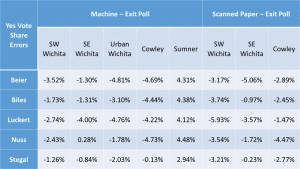
– “The relatively low response rate for provisional ballots and relatively high rate for the scanned paper ballots at the Urban Wichita and Sumner County sites indicate that some provisional voters mistakenly marked that they had used a paper ballot.” Sounds reasonable, but this is not a minor detail, but, rather an important indication that option (c) above (inadvertent errors in describing behavior by poll respondents) is in evidence. Poll respondents who mistakenly misreport their method of voting can, equally, misreport how they voted.
My response:
Actually, no, I would disagree that they can equally misreport how they voted. Being mistaken about which type of paper ballot was used is an understandable and easy error for people to make. If the provisional voters have differences in their choices (a question that has not been answered), it will lead to bias in results if they are included.
Mistakenly answering Yes versus No can be expected to be a considerably less frequent error. It’s also reasonable to assume that inadvertent errors of that nature will be randomly distributed among all responses, so such errors – as I explicitly assumed and this reviewer rejected as “crazy” – will be randomly distributed around zero and relatively small. Thus, no bias is expected from such errors. This is an important distinction between the two types of inadvertent errors, since bias is what we are attempting to measure and then attribute to machine rigging. I’m not sure how to revise the paper to deal with this criticism. I will have to give it considerable thought.
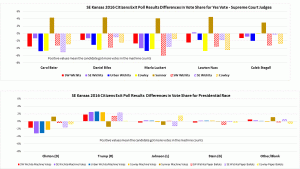
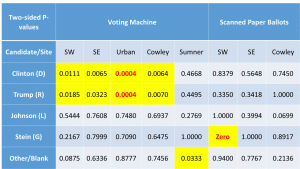
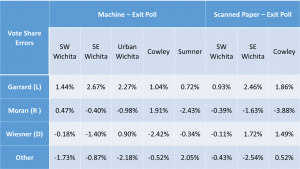
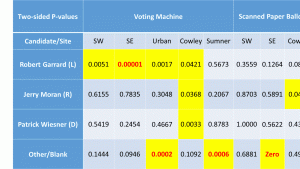
– Figure 5 shows a statistically significant Democratic effect. The authors briefly assert that, “the potential sampling bias is not large enough to explain the SCJ results” (p. 11) without providing a better sense of magnitude.
My response:
This is a valid criticism I can use to improve the paper. To sense the magnitude of the difference, readers would have to compare the appropriate values from two different tables. I will add an explicit statement of the difference in magnitude and additional points or lines to the graphs to make this clear.
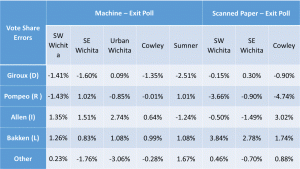
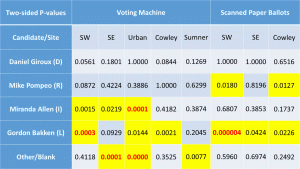
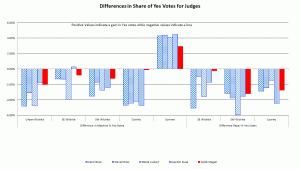
– What should be compared is distributions because all of the races feature multiple options, and an analysis of only a scalar (Republican vote share or Democratic vote share or “Yes” share) is incomplete. This is a simple point the author correctly broach, and that the ANOVA acknowledges (though with collapsing of abstention of “other” voting). However, this key point is ignored in their main work, as when they dwell on the yes votes for the KSC justice retention races on pages 7-9. Voting options in the SC contests were not 2 (Yes or No), but, rather, 3 (Yes, No, and Abstain/Leave Blank). These authors drop the item non-responses as though they are random and ignore the important blank/abstain shares in the main analysis, and neither move is wise.
My response:
This is a valid criticism of the analysis technique used for the judges; it’s the sort of technical nit to pick that academics like to argue over but has no impact on the results. I actually ran both types analyses and the results were very similar. I didn’t want to include both and deliberated for a while on which one to include. I ended up choosing to go with the two responses, yes and no, rather than including the non-responses as a separate category because it’s a simpler cleaner analysis for non-statisticians to understand. I’ll reconsider which to include, but even if I switch to the other type, it only changes the numbers in some tables and bullet points. Using the other approach doesn’t change the conclusions at all.
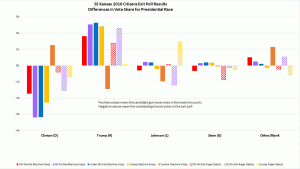
– What jumps out of Figure 3 is that the Sumner results appear to be different in kind from the other 6, insofar as all judges’ yes vote shares in the exit poll exceeded their official yes shares. The obvious candidate for an explanation is not that the cheating was of a distinct form in Sumner, but that the people implementing the exit poll forgot to include a “left it blank” option on the survey form. Apparently, more of the poll respondents who did abstain chose the wrong answer “Yes” than the wrong answer “No”, rather than leaving the poll question blank too. That pattern was un-hypothesized and is mere surmise on my part. The details of the survey matter a great deal and the blunder of omitting one of the options changed the conclusion greatly. It was a useful mistake! In that light, it is startling that the authors are so relaxed about alleging fraud based on the survey-versus-tabulation comparison, on the premise that the other surveys cannot possibly been biased or wrong in any way.
My response:
I have a definite defensive reaction to calling this difference a blunder or mistake. It was a deliberate decision made by the manager of that exit poll due to space considerations. He also included questions about other races unique to his location so space was at more of a premium for his survey form than others with fewer questions. I disagree that this difference would cause the difference seen in Sumner county, but cannot prove it. However, even if this data was dropped from the results analysis, I would still have better than 99% confidence the other sites show signs of voting machine rigging. Accepting this concern as legitimate and removing this data from the analysis would not alter the conclusions of the paper.
– Bishop, in POQ in the 90s, reported an experiment to show that it seemed to matter if exit polls were done as face-to-face interviews or as self-reported surveys. Arguably, that article showed that merely emphasizing secrecy by marking the form “Secret” helped improve response rate and accuracy (the latter is not fully clear and would not be the right conclusion in the world where tabulations are all suspect, inhabited by these authors). It would be helpful to know exactly how the volunteers who administered these exit polls obtained the answers.
My response:
Details about how the survey was conducted was included in an earlier version of this paper, but in my efforts to reduce it to an acceptable size, I may have cut the section describing how the survey was conducted too much. I can make this clearer by putting back my original longer write up for this section.
– “In order to drive down the size of the error that could be detected, we needed the sample size to be as large as possible relative to the number of votes cast.” Misleading. The effect of getting high coverage are conditional on no error in responses (deliberate in the case of socially desirable answers, inadvertent in the case of busy/distracted/annoyed respondents participating with reluctance or hurrying, etc.). And, of course, non-response is critically important, because contact is not measurement. One might use these data to compute how different the non-responders would have to be from the responders for the official data to be correct under and assumption of no-error-in-poll-responses. That would be a bit interesting, but the assumption would be hard to justify, and I’d still be disinclined to jump on the fraud bandwagon. My strong suspicion is that admitting to all of the possible sources of discrepancy will make it clear that it is not wildly implausible that those who wouldn’t talk to pollsters were a bit different from those who would and that alone could generate the gaps that so excite the authors.
My response:
I actually did compute how different the non-responders would have to be as this reviewer suggested. The results were not particularly illuminating to me and I did not include it in the paper. However, this reviewer is not the only person to have suggested it so I will include it in the next revision.
Reviewer: 2
Comments to the Author
The manuscript looks at a recent vote in Kansas and argues that the machine counted votes were manipulated.
The authors state that the best way to verify a vote count when one has no access to the voting records is an exit poll. I have two problems with this. First, exit polls have many problems and are usually regarded as less reliable than normal random sample surveys.
My response:
This seems to be a serious bias against using exit poll results as a method of verifying election accuracy. Exit polls as standardly done in the US do have many shortcomings with regard to being used to detect fraud. That was why I did not use a standard method but designed my own approach based on my statistical and quality engineering background.
Second, many alternative approaches exist that have not been discussed and build on work by Mebane, Deckert, Beber and Scacco, Leemann and Bochsler, and many others. These approaches often but not exclusively rely on Bedford’s law and test empirical implications of specific forms of fraud.
My response:
This is useful to me as it provides direction for further research. My suspicion is that the alternative approaches being referenced would require resources that are not available to me, but I will look into these authors to see if I can learn something that will improve my paper and future research.
The argument that the common tendency found in the US has to be attributed to fraud is baseless. The authors only provide one citation from a non-peer-reviewed source and do not provide other arguments to justify this claim.
My response:
This is referring to the book “Code Red” also denigrated by the first reviewer. What I was trying to express with that citation was the justification for considering the hypothesis my exit polls were set up to evaluate. I will definitely have to revise this section.
The discussion of stratified vs clustered sampling is unclear and the conclusion is confusing. The authors also mention that participation rates were excellent without providing the rates.
My response:
The discussion of stratified vs cluster sampling and the participation rates was a section that suffered from cuts made to reduce the length.
The main problem is that the authors assume the exit poll to provide something like a true benchmark.
My response:
This seems to be a serious bias against using exit poll results as a method of verifying election accuracy. These Exit polls provided the citizens of southeast Kansas with the best possible benchmark obtainable given the voting equipment and processes used in Kansas. That this benchmark is not acceptable to academics should imply that the voting equipment and processes used are unacceptable given that no other means of verifying the vote count is available to citizens.
But it is one of the fundamental lessons of social science polling that participation is correlated with socio-economic background variables. Education and survey participation are usually positively correlated and have to be corrected. Since these factors are also correlated with vote choice there is no reason to expect the exit polls in their raw form to be anywhere close to the truth.
My response:
This criticism is based on the lack of understanding of the cluster versus stratified sampling approach and the details of how the comparison was made. Using the cluster sampling approach and comparing the results by precinct and voting equipment allow us to dispense with the complicated process of adjusting the exit poll results by such factors as education level or income or race which is required when using stratified samples. The use of that technique allows for better predictions for the larger population and a more in-depth analysis of who’s voting for whom, but makes the direct comparison for the purpose of assessing the accuracy of the voting machines untenable.
In fact, Republicans are less likely to participate. The supplied ANOVA test for some implications is unclear and I would want to just see the plain participation rates correlated across all districts controlling for average education. But the non-response bias would perfectly line up with all findings and this is then the entire ball game.
My response:
Definitely need to rewrite the ANOVA analysis section. The ANOVA test showed a bias in responses against Libertarians and for Democrats but Republicans overall had bias either direction. Whether that bias is due to inherent characteristics of the party members or by rigging by the machines can be debated. The ANOVA showed that the size of that bias wasn’t enough to account for the discrepancies observed in the Supreme Court Judges and that was after assigning the democrat bias to the 4 Republican justices that Brownback opposed.
I can agree that it was be interesting to run the correlation suggested, the average education of voters by precinct is not available for Kansas precincts and I do not have the resources to compile such a database, even if only for a few counties in Kansas.
I feel that it is extremely difficult to successfully argue along these lines. The authors fall short of being fully convincing on key points. Given this and so probable alternative explanation, I feel that this paper does not achieve of what it sets out to do.
My response:
This is the bottom line for both reviewers really. I wasn’t convincing enough. I’ll have to try again.
I’m not sure what the best approach would be and appreciate any suggestions my readers have. Should I continue to try to limit the length of the paper to make it acceptable for academic publications or should I include all the information and analyses results that reviewers and readers could reasonably want to see but that inflates the length to beyond what peer-reviewed publication will consider?
If I go with the longer paper, I am basically limited to self-publishing without peer-review which is then easily dismissed by anyone who disputes the conclusions, such as the Kansas Secretary of State’s Office.
Should I seek publication in another field or a general scientific research publication? It’s less likely to get any notice by people with the ability to change our voting processes if I do that, but it would be available as a peer-reviewed reference to people who are trying to make improvements and eliminate paperless voting machines and institute auditing procedures when machines are used.
These are the questions I will ponder as I revise my paper again.